Indexing My Blog’s Links
Sometime ago, I don’t know when, an idea struck me: what if I could see all the outbound links on my blog? Could I peer into which sites I link to most frequently? It seemed like a relatively feasible idea as my blog is powered by a static site generator. So I jotted down the idea and forgot about it.
Fast-forward to a few days ago, I was sifting through some notes of old ideas (many of which had me asking my old self why I thought any of them were any good) and I found this idea. I was in the mood to write a little code, so I fired up my code editor and started tinkering with my blog’s build. Pretty soon, I had a collection of all the links on my blog. The task before me was to make sense of them all and display them on a page. What follows are some notes on this whole matter.
Getting a List of All Links
All my posts are in markdown and I use marked.js to transform my markdown to HTML. marked.js provides a tokenizer for <a> tags, which I can hook into as the renderer is turning all the markdown into HTML. This allows me to analyze every single <a> link in a markdown file, parse its href into a URL with its component pieces, and create a collection of links grouped by domain. Example:
// assuming I've imported marked.js and psl
let linksByDomain = {};
markedJsRenderer.link = (href, title, text) => {
// Capture any relative links and note them as coming
// from my blog. Otherwise parse the link and get the hostname
let hostname;
if (href.startsWith(".") || href.startsWith("/")) {
hostname = "blog.jim-nielsen.com";
} else {
hostname = new URL(href).hostname;
}
// Turn the hostname into just the domain for even
// better grouping then add it to our collection of links.
let domain = psl.get(hostname);
if (linksByDomain[domain]) {
linksByDomain[domain].push(href);
} else {
linksByDomain[domain] = [href];
}
// Other code here
};
Note how I’m grouping all the links by primary domain instead of just hostname. I initially grouped them by hostname, but I realized that was giving me results like this:
github.com- 50 linksgist.github.com- 5 linkshelp.github.com- 2 linksgit-lfs.github.com- 1 linkblog.github.com- 7 links
Rather than this, I wanted all links to the domain github.com to be grouped together so I could see “github.com - 65 links”. But getting the domain without the subdomain isn’t as easy as one might think. You can’t say, “start at the last period and give me whatever you see until the next period.” That might work for google.com but it wouldn’t work for google.co.uk. Parsing the domain suffix can be a bit tricky and for that I relied on the psl which is a JavaScript domain name parser based on the public suffix list. This allowed me to group (mostly) all links from a single domain together so I could easily see how many times I linked to anything on a domain like github.com.
Displaying All Links on Screen
Once I modified my build step to parse all links, I now had an object representing every single link on my blog, grouped by domain. Example:
{
"github.com": [
"https://github.com/username/link/to/something",
"https://gist.github.com/another/link",
// more links here
],
"twitter.com": [
"https://twitter.com/username/019237029381",
"https://twitter.com/username/192370293812",
// more links here
],
"mozilla.org": [
"https://developer.mozilla.org/reference/article",
"https://developer.mozilla.org/docs/link",
// more links here
]
}
Now I could take that data and dump it into an HTML page somewhere on my site — I went with /external-links/.
I contemplated how I wanted to display this information. A list? A table? Maybe some HTML + JavaScript for a fancy interactive widget of some sort? I could’ve dumped this information into my page in a myriad of ways, but I opted to use the (rather new) <details> element. It provides me a nice way to show the top-level information about my site’s links (where am I linking to and how many times) with additional information that expands/collapses when you want/need it. The best part? I didn’t have to write any additional JavaScript to get this kind of basic information interaction. It’s all supported natively in HTML.

A Few Observations
There were a couple things I learned while doing this that I just wanted to make note of:
1. Broken Links
Trying to parse every single link on my site helped me realize I actually had a couple broken links! The parser failed in a few different places, so I would console.log the href where it was failing and found that either:
- I was linking to bare domains, i.e.
href="google.com" - My markdown was wrong. I had extra parenthesis around things, i.e.
[google]((https://google.com))resulting in anhrefwrapped inhref="(https://google.com)".
There were about four or five cases like this, which I was able to fix. Having to programmatically parse and index every link on my site was not only useful for informational purposes, but it was a kind of automated quality assurance that ensured none of my links were broken. Going forward, if I ever write the wrong syntax for a link, my build will yell at me.
2. Sad Links to Corporations
While I saw a number of links to the domains of individual people on the web, it felt a bit sad to see a number of links to independent voices lost in corporate domains. For example, rather than johndoe.com I saw medium.com/@johndoe.
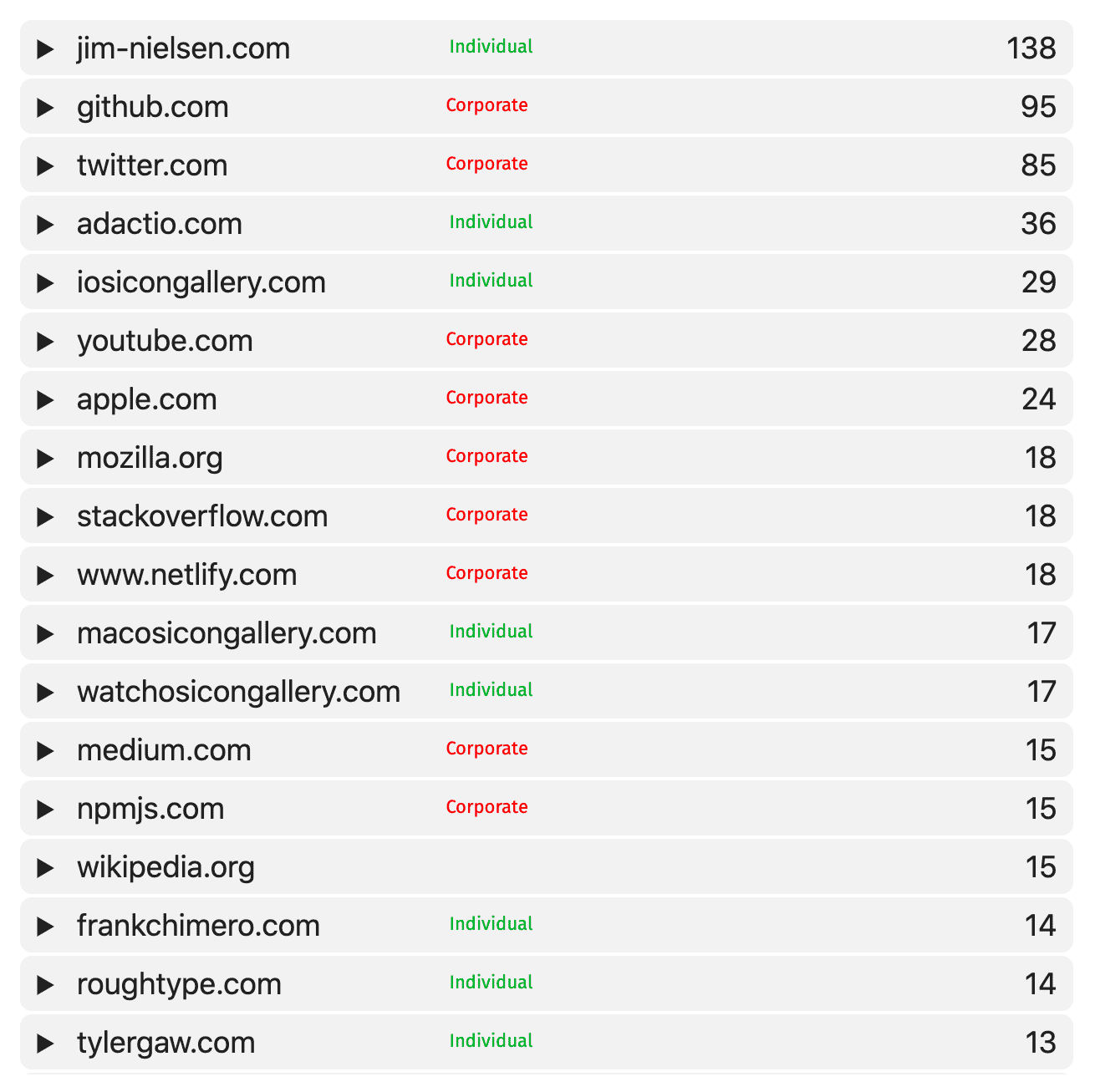
You might not think this is a big deal, and maybe it’s not, but I love the idea behind the indie web: a people-focused alternative to the corporate web. Seeing everything you’ve ever linked to in one place really drives home how much of the web’s content, made by individuals, is under corporate control and identity. Take a look at the most-linked-to domains from my blog:
3. Inbound Links
Everything I’ve talked about in this post has to do with things I link to, essentially outbound links. What would be really interesting would be to see all the inbound links coming to blog.jim-nielsen.com. Analytics services, like Netlify, give you some insight into this kind of thing, but it’s in no ways comprehensive. If I controlled the server which served inbound requests to blog.jim-nielsen.com I might toy with this a bit more, but I do not so I cannot.
4. Diversity of Links
I think it would be interesting to anyone to see the diversity of sites and people they link to. Not that outbound links are necessarily a concrete reflection of any kind of bias—it all depends on the purpose of your site—but if you’re willing to be open, they will tell you something.
Seeing that the top site I link to is myself, well that wasn’t really a surprise. I suppose that just confirms my own narcissism. No, but really, my blog is primarily a writing reference for myself. I use it to write about and join ideas that are swirling in my head, so it’s no surprise to see blog.jim-nielsen.com as the most frequently occurring domain to which I link.
Others high on the list are no surprise. Twitter, Github, MDN, StackOverflow, those are all frequent developer references that cracked that top ten. Seeing adactio high up on the list is also no surprise (I probably would’ve guessed Jeremy would be higher). Seeing my icon galleries as well as apple.com on there is no surprise because I’ve written a few posts behind how I build those sites, with a high number of links to the galleries or the specific app icons in the App Store. So no real surprises there.
In short, nothing here was incredibly surprising. In fact, a lot of the sites in that list are a mirroring of what sites I subscribe to in my RSS. Big surprise, eh? It really drives home the point about diversifying the things to which you expose yourself—something I need to think and act on more frequently. I don’t think I needed an index of all my outbound links to realize that, but it serves as a mirror to that fact anyway.
Conclusion
Because this was actually relatively straightforward thing to do, I might spend some time in the future figuring out how to make additional ways of viewing this same information. For example, imagine some kind of auto-generated visual that shows a map of all these outbound links? In other words, a more visual way of seeing where all my links are going. That could be really interesting.
What would be even more interesting is if more of people did this: exported a list, a visual, something that depicts where their personal sites, blogs, etc., link to. I suppose it’s really just the view Google has of any of our sites. Nonetheless, now I have a view of all my linkings and not just you Google.