Webster’s Dictionary Defines “View Source” As...
I wrote previously about the spirit of view source but didn’t get out everything I had to say. Since this is my blog and I can say what I want, here’s some more observations about view source.
There’s been a debate the last few years whether keeping “View Source” as a feature remains relevant. Tom Dale, Chris Coyier, Jonathan Snook, and Chris Heilmann have all weighed in on the matter. I’m not here to add my opinion, but I do want to make a couple observations.
First, when we talk about “View Source” what precisely are we talking about? I think this is an important point to clarify, as it sometimes goes unsaid and therefore a lot of assumptions sneak into the conversation and we might realize we’re not all talking about the same thing.
In this post, I specifically want to talk about the idea of viewing the source HTML of any given website. But what does that even mean?
What Does “View Source” Mean?
Referring to HTML specifically, if someone says they want to “view the source” of a web page, what are they talking about? Conceivably, they could be talking about one of three things:
- View source code (the code that generates the HTML delivered over the network)
- View page source (the HTML delivered over the network)
- View runtime source (the living HTML, a.k.a the DOM)
View Source Code
I doubt many sites on the web today are authored in HTML. The HTML that gets delivered to the browser over the network is likely the result of a computer somewhere stitching together raw content with coded templates, then minifying it all for optimal delivery over the network (in the case of SPAs, some of this process takes place on the client).
When someone says they want to view the source of a webpage, they could mean they want to view the source code that generates the HTML that gets delivered to the browser at request time (or in the case of SPAs, the source code that generates the HTML that gets injected into the DOM at runtime).
View Page Source
This is the early days of the web interpretation of “View Source”. I call it “View Page Source” because that’s how most browsers have implemented this feature (a topic I’ve written about previously). It refers to the ability to view the original, unformatted HTML as delivered to the browser over the network at request time. This may or may not be the format it was authored in (see point above).
Before JavaScript runs, before CSS paints, this is what the browser is looking at. In the beginning was HTML.
View Runtime Source
I call this one “View Runtime Source” because what you’re really trying to do is view the HTML that is powering the website that you’re looking at in its current state. In other words, view the DOM (accessible via the DevTools).
It’s worth noting that this representation of the page’s HTML could be the same, slightly different, or drastically different than the code you see when you “View Page Source” (i.e. the HTML delivered over the network at request time).
“View Runtime Source” is a bit of a Schrödinger’s cat scenario: what the HTML for a given web page looks like is dependent upon the moment in time in which you look at it.
View Runtime Source vs. View Page Source
I wanted to try comparing and contrasting two different perspectives of HTML: “View Page Source" (the HTML at delivery time over the network) and “View Runtime Source” (the HTML after page load, upon time of inspection).
I chose two “pages” that I guessed were probably quite different from each other: a page on CSS-Tricks and the Twitter home feed and diffed their “page source” and “runtime source”.
How I Did It
I used the following, completely non-scientific yet still interesting approach:
- Load the page in a browser.
- Choose “View Page Source”.
- Copy/paste into an HTML file named “before”.
- Open DevTools, choose the root element, and select "Copy HTML".
- Copy/paste into an HTML file named “after”.
Once I had the before and after HTML files, I put them a diffing tool and started reading. As I parsed the differences, I took the notes you see below.
A Note on My Process
The “before” HTML I looked at was the raw HTML sent over the wire. The “after” HTML I looked at was a stringification of the DOM after a couple seconds of first requesting the URL. The string is a representation of what the browser decides to output if you click “Edit as HTML” on the root DOM node and then copy it. In other words, it’s the browser’s version of saying “you input HTML, I parsed it, executed relevant JavaScript, and now have this HTML representation.”
Because of this, there were diffs in the HTML that represented side effects of the approach and not necessarily intentional HTML differences. For example: the browser might read in decimal code values (i.e. & ) in the “View Page Source” version of the HTML, but then convert them to an HTML entity when you “stringify the DOM” (i.e. &). A lot of these kinds of differences showed up in my diffs and I may mention some of them but not all of them.

As another example: all single quotes in the “View Page Source” HTML were converted to double quotes—for example on attributes, type='text' was turned in to type="text".

One more example: some tags were converted from self-closing tags as to opening/closing tags, i.e. <meta /> and <link /> tags were changed to <meta> and <link>.
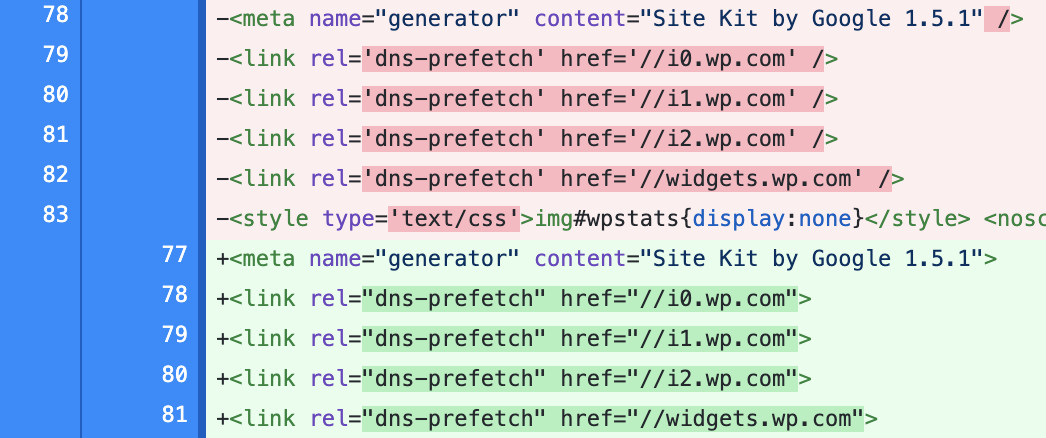
It is worth noting that I saw this same phenomenon in SVG, i.e. <path /> gets changed to <path></path> by the browser.

Apparently there are some rules around this when writing SVG in HTML—at least according to StackOverflow:
You can write a path as
<path></path>or<path/>but you can't write it as<path>
And in HTML as well—according to StackOverflow
Using the self-closing syntax in HTML5 is valid (but only for void elements, such as
<br/>; or foreign elements, which are those from MathML and SVG).
While interesting, I omitted most observations on details like this because they pertain more to implementation details of the browser’s choices on parsing HTML (and my general approach to this experiment) and less to what the developer’s intentions were in manipulating the source HTML delivered over the network upon page load.
Diffs for CSS-Tricks
Source page: “Using WebP Images” on CSS-Tricks.
You can see an image of the source diff I parsed through.
{kind=link}
What follows are the primary differences I observed around how the source HTML was manipulated by the execution of JavaScript upon page load.
html/body Class Additions
Pretty standard stuff: adding and removing classes at the document level. Likely used for styling things based on whether JS is present. Sometimes you can tell just by the name of the class.

You can see it happened with the <body> tag as well. woocommerce-no-js to woocommerce-js.

Why not add all classes to the html or body tag only? I’m going to guess these are third-party JavaScript instructions used as plugins on the page, so there’s no real concerted effort by a single team to be holistic about the approach.
Directly After Body
As you may have noticed from the above screenshot, other stuff changed right after the opening <body> tag. “Directly after the <body> tag” is a pretty standard place JavaScript likes to stick stuff.

If you try to parse through it, it looks like some custom <style>s from a plugin (#fit-vids-style) as well as some ad injection from buysellads.com. Again, likely third-party JavaScript written by independent teams staking their claim in the DOM as plugins.
Google Analytics Injection
Google Analytics getting its place in here. Based on its position in the diff, I’m going to guess there’s some greedy logic behind its particular placement (an “I want to be first” attitude). I’m going to guess the logic is something like “find the first <script> element on the page then inject Google Analytics right before that.”
![]()
Ad Injection
Some ads getting injected into their placeholders that shipped in the HTML that came over the network.
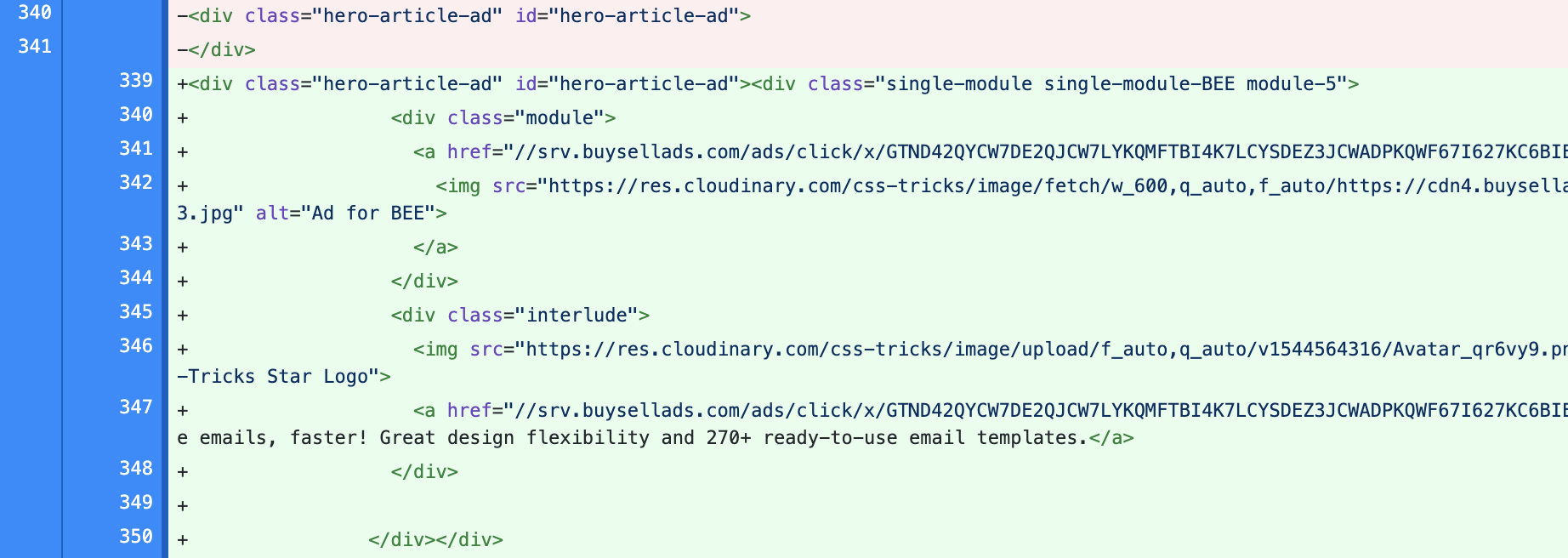
For what it’s worth, there were a number of “placeholder <divs for ad injection” throughout the diff.
Anchor Links for Headings
This was an interesting diff I stumbled on:

It looks like some JavaScript is going through the document and dynamically adding anchor links to each of the headings in the post content.

I’ve always approached this by having the build process for my content parse the headings, turn them into slugs (i.e. “This is My Heading” → “this-is-my-heading”), and turn them into anchor-able links. This approach is different in two ways.
First, the anchor-ifying of headings appears to take place on the client, not the server. I’m not sure what the advantage of this might be? Could be a constraint of the way the page is authored and then put together and served? Even then, because this is client side, anchoring directly via the URL with an id would break the default browser behavior of moving you down the page to that element because the id in the URL wouldn’t be found in the document at load time. It’s only after JavaScript has been parsed and executed that the id gets injected in the page. So whatever JavaScript is doing this anchor-ifying of headings must also be jumping you down the page as well.
Secondly, the id attributes in this case seem to be agnostic of their content. It looks to be dynamically adding an incremented counter to each headings as it goes down the page. I’m unsure of the why behind this approach as well. My best guess would be: headings are probably more likely to change in wording after publication but less likely to change in position, so content-agnostic headings result in fewer broken anchor links over time? I don’t know, that’s my guess.
Either way, this approach made me pause and think about how I generally approach this problem, which was good. That’s kind of the point of this whole exercise.
Image Lazy Loading
This kind of thing happened a lot in the post content area. Seems pretty standard. This particular implementation looks like a third-party plugin that’s handling it all.
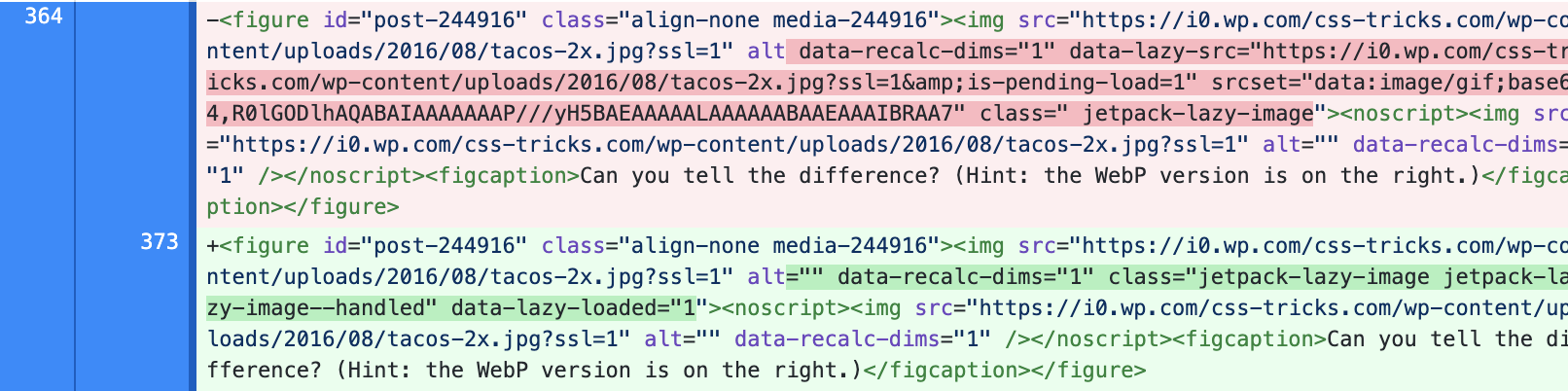
One day we’ll get solid support across browsers for native lazy loading and this kind of thing will (hopefully) become obsolete.
Syntax Highlighting
It looks like syntax highlighting is happening on the client, rather than being delivered in the initial HTML. I thought this was interesting, especially since I've always done syntax highlighting on the server in my build process, such that the markup to support syntax highlighting gets delivered in the initial HTML.

I’d never really considered this, but I suppose you could argue that doing syntax highlighting on the client is a “progressive enhancement”? Let me think out loud for a minute: the source code delivered in the initial HTML is actually more readable when it’s source code devoid of all the <span>s that wrap the individual pieces of code purely for stylistic purposes. In other words, the pure code in HTML (devoid of all markup required for syntax highlighting) is more human readable. For example, just look at this snippet. If JavaScript didn’t load for this page, this code markup would remain incredibly readable—more so than if you wrapped it in the markup required for syntax highlighting on the server and delivered it in the initial HTML to the wide variety of clients that might request it.

As previously noted, I’ve always baked the syntax highlighting markup into the server-side HTML, but this approach has made me reconsider that—at least for a moment. Again, more reason to read other people’s code.
Related Posts
Related posts appear to get loaded dynamically by JavaScript (into a placeholder <div> in the original HTML). Makes sense. They’re not required to understand the current document, so “enhancing“ the page with them seems like a good approach.

Personally, I’ve found myself doing this on some projects as well. Being able to have a single index you updated periodically and then fetch dynamically on the client to generate a list of related posts often makes more sense than having to regenerate the “related posts” for every single page you’ve ever made all the time.
Diffs for twitter.com
Now let’s turn and look at a totally different way of doing a web page. For this example, I logged in to Twitter and looked at the source for my feed.
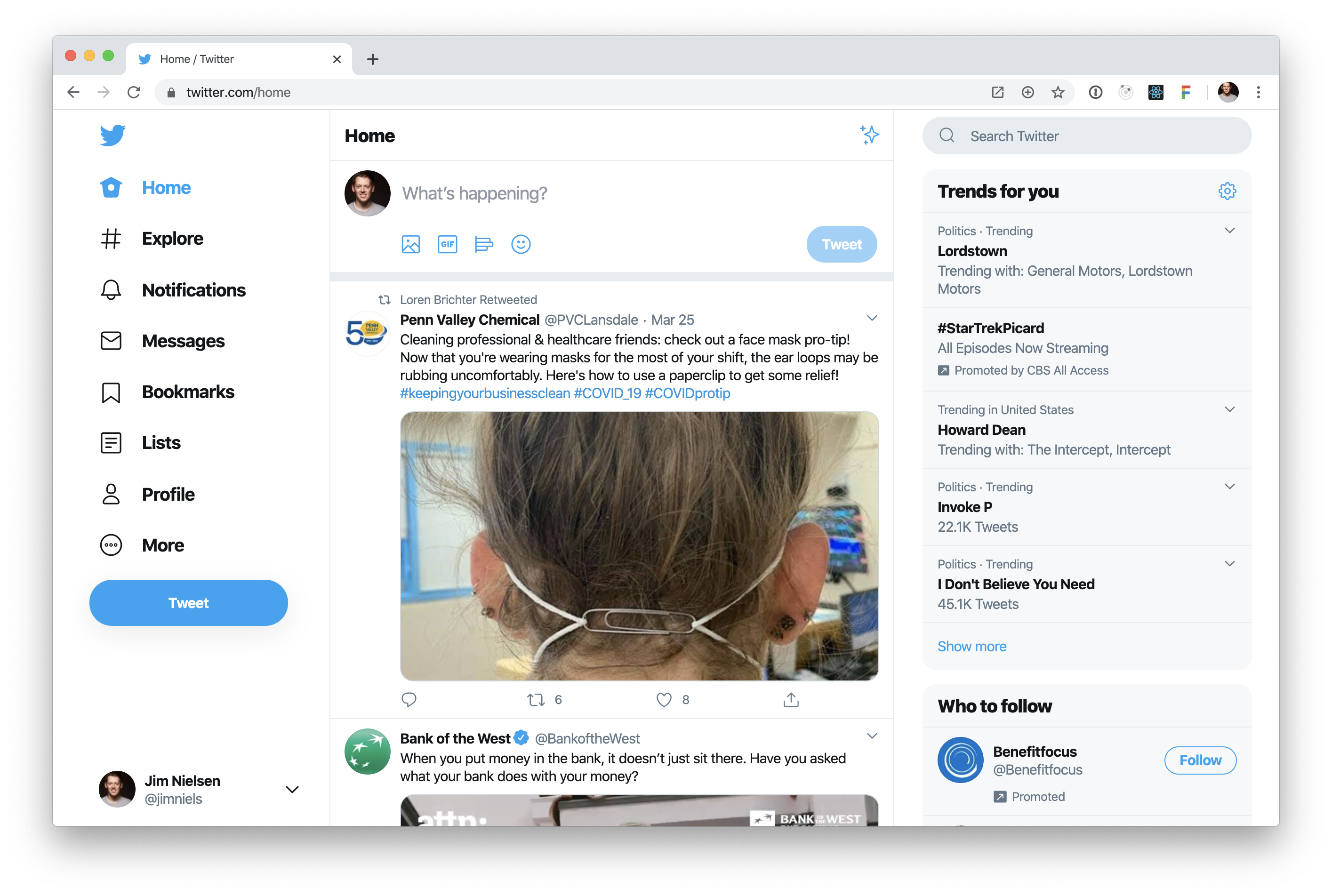
react root
The only major diff on this site was, well, everything. There was a single root node where the entire content of the document got injected. In contrast to the css-tricks example above, this is obviously a very different way of approaching building for the web. “View Page Source” becomes less relevant in this world because no functional content is shipped in the HTML over the wire. All relevant content comes in after the initial page load and therefore will only be visible in the HTML at the time of “View Runtime Source”.
For kicks and giggles, I actually measured the diff and here’s what it turned out to be:

As noted in the image, you can see that the diff screenshot from HTML over the wire (View Page Source) vs. HTML at runtime (View Runtime Source) is ~24,000 pixels tall. It was a lot of code injected after the initial page load.
nonce
One small thing I learned from Twitter’s HTML over the wire was this thing called nonce. StackOverflow
the
nonceattribute is way of telling browsers that the inline contents of a particular script or style element were not injected into the document by some (malicious) third party, but were instead put into the document intentionally by whoever controls the server the document is served from.

nonce is a way of indicating that a particular tag came over the wire and wasn’t injected at runtime. Again, it’s useful to make a distinction between what kind of “source” you're looking at when you read an HTML document.
Summary
We often talk about the different approaches to building for the web: serving an entire page at request time and enhancing with JavaScript vs. serving only a bare shell and injecting all content at runtime via JavaScript. But it was an interesting experiment for me to actually dig into the actual implementation details of what that means in the light of “View Source”. I think it’s worth stating once again that when we have conversations about the relevancy of “View Source”, we should define exactly what we mean by the term because viewing the HTML over the wire isn’t the same thing as viewing the DOM in the DevTools.