Using Quadratic to Discover Newsletter Links
I built myself a daily email digest that informs me who is linking back to my blog.
It’s a fun way to discover new people, blogs, and newsletter that I didn’t know existed.
I recently saw links to my blog from the tldr newsletter but didn’t know which posts specifically they were linking to.
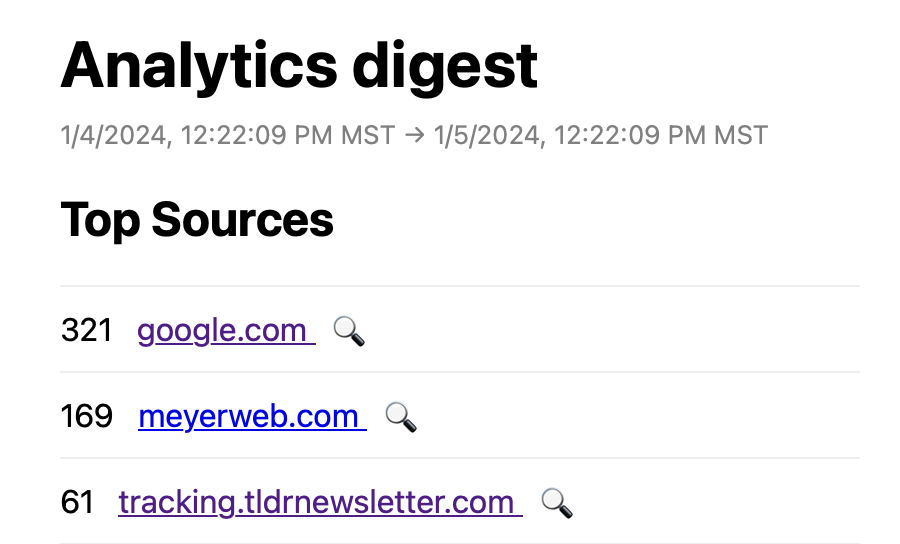
I visited their site to find out, but it appeared to be an archive of daily newsletters. I realized it would take way too long to go through every newsletter trying to find a link to my blog.
So I tried doing a site-specific search, but their domain didn’t appear to be indexed by Google as there were zero results. Bing and DuckDuckGo didn’t have any useful results either.
I could’ve just stopped investigating at that point, but my curiosity was triggered. “Oh yeah, think you can hide your links from me?” I thought.
Challenge accepted.
I started investigating their site structure and discerned that all their newsletters were archived by date following this pattern:
tldr.tech/:category/YYYY-MM-DD
For example:
tldr.tech/webdev/2024-02-02
Once I discovered that, I was already writing a script in the back of my head that would fetch one newsletter per day, going back 30-60 days, and find any links to blog.jim-nielsen.com.
The cumbersome part about doing something like this is getting all the tooling in place to do it. For example, as a little node script, I’d need a couple packages off npm (e.g. for parsing HTML and finding links). Then it’s a matter of writing some code, running the script, logging stuff to the console, tweaking and repeating until I have what I want.
But then I thought, “Wait a second. This is a perfect use case for Quadratic!”
(Quick aside: Quadratic is the developer-focused spreadsheet I’m working on for my day job. Imagine if Excel and Figma and VSCode had a baby. That’s Quadratic. A spreadsheet, on an infinite canvas, that runs code. Granted right now it’s only Python code, and I’m no Python expert, but it has AI integration so novices like myself can quickly ask things like, “How do I add data to an array?” And it will give me back working code. So I can become productive quickly.)
Quadratic was a fabulous tool for this scenario because:
- I don’t want to setup (and maintain) a whole environment to run a little script (node + npm + 3rd party packages, etc.) This all runs in the browser, so all I need is a URL and “it works on my machine”.
- I want to visualize the data I’m working with. Rather than just logging strings of JSON data to the console and parsing/tweaking as I go, Quadratic lets me render data to the structured grid of a spreadsheet. This makes it easy to do things like: fetch data, render to column 1; read data from column 1, filter, massage, do logic, then render to column 2; highlight resulting data as the answer I’m looking for!
- I can share the results of whatever I discover easily by copy/pasting a link.
So I opened up Quadratic and wrote a little script. It:
- Creates a list of dates going back
nnumber of days, e.g.['2024-01-29', '2024-01-28', '2024-01-27', ...]. - Fetches[1] the HTML for each of those dates from
tldr.tech. - Uses Python’s Beautiful Soup to parse the HTML and pull out all external links.
- Render the links to a column in the spreadsheet along with what newsletter date they were found in (and print to the console any newsletters it didn’t find).
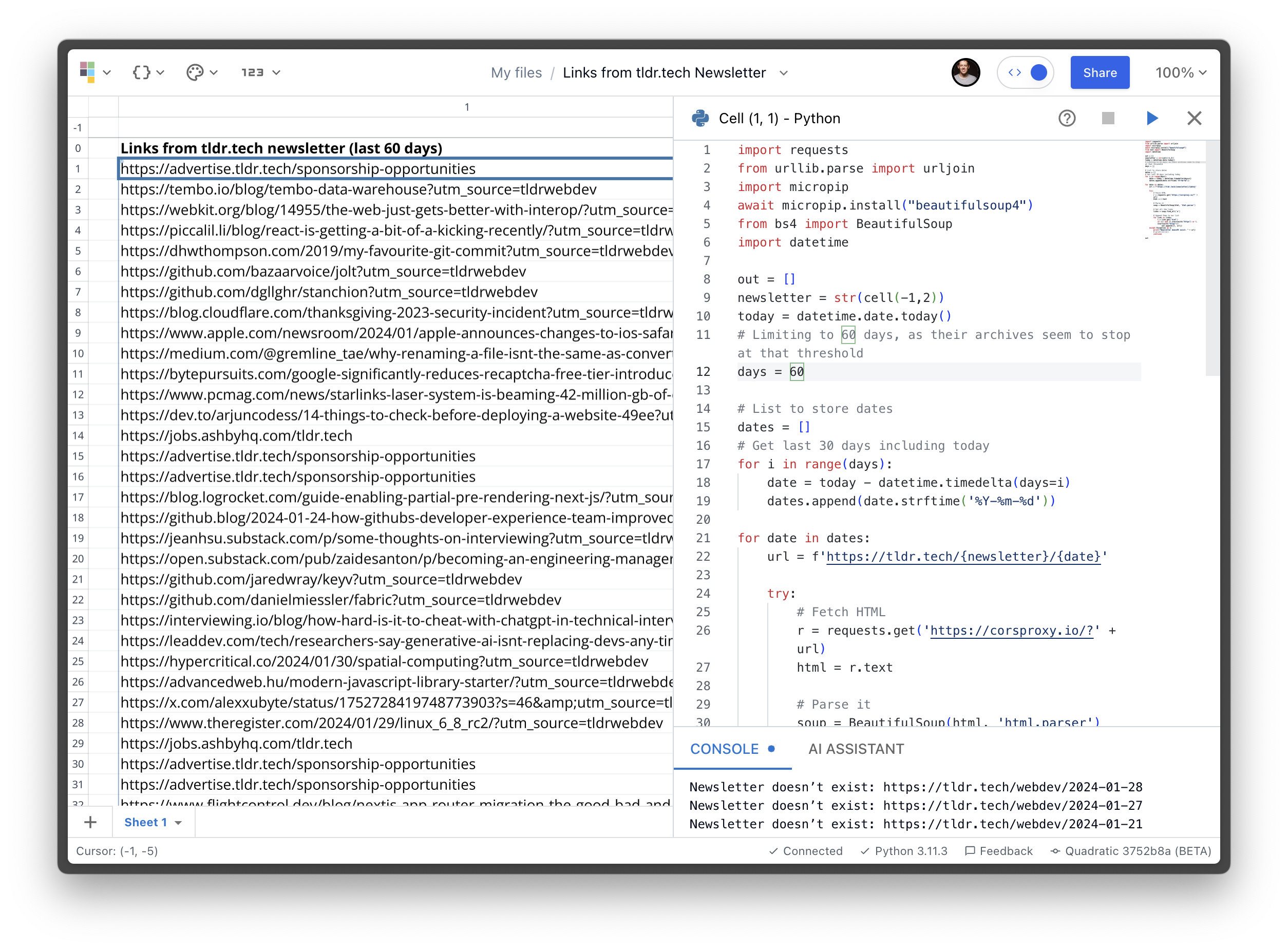
Kind of a lot of data to fit into a small screenshot, but here’s what you’re looking at:
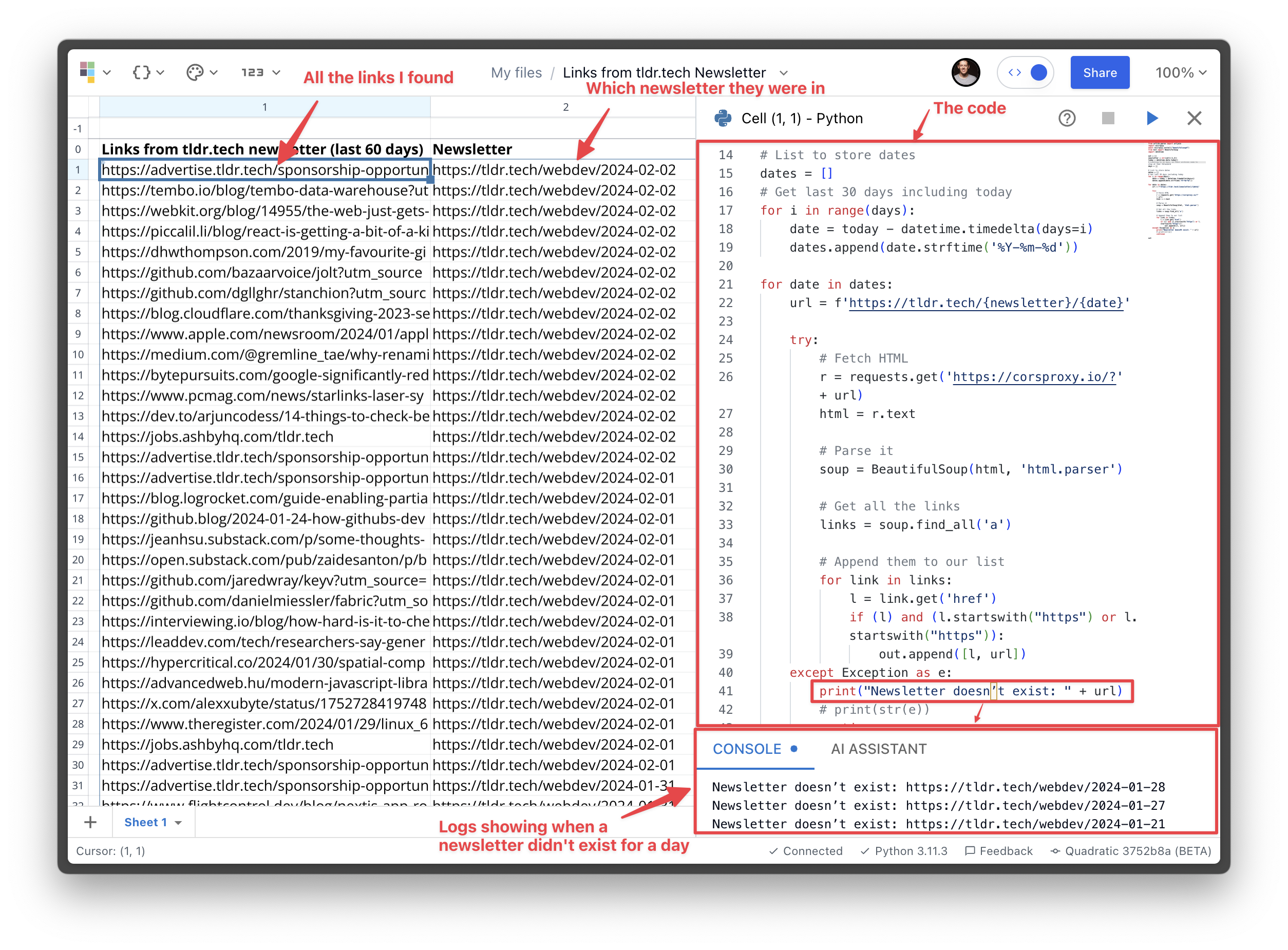
A lot of links! The spreadsheet lives on an infinite canvas, so it’s easy to zoom out and see the shape of the data I’m looking at:
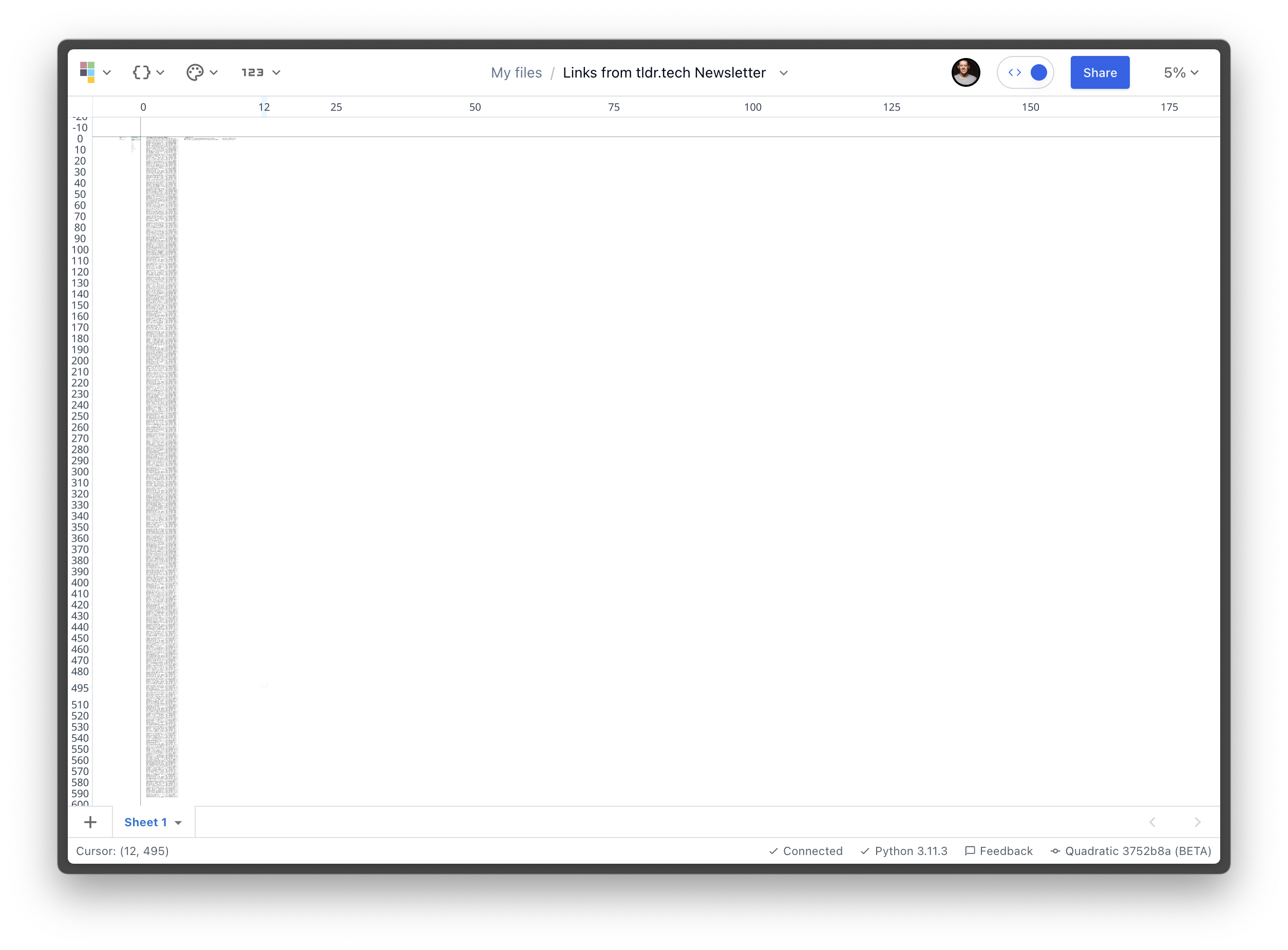
Approximately 600 rows of link data!
Now that I have all the raw data in a column in the sheet, I start another column of data that reads in the first column of links, looks for ones that contain blog.jim-nielsen.com and then renders that to the sheet in a new column.
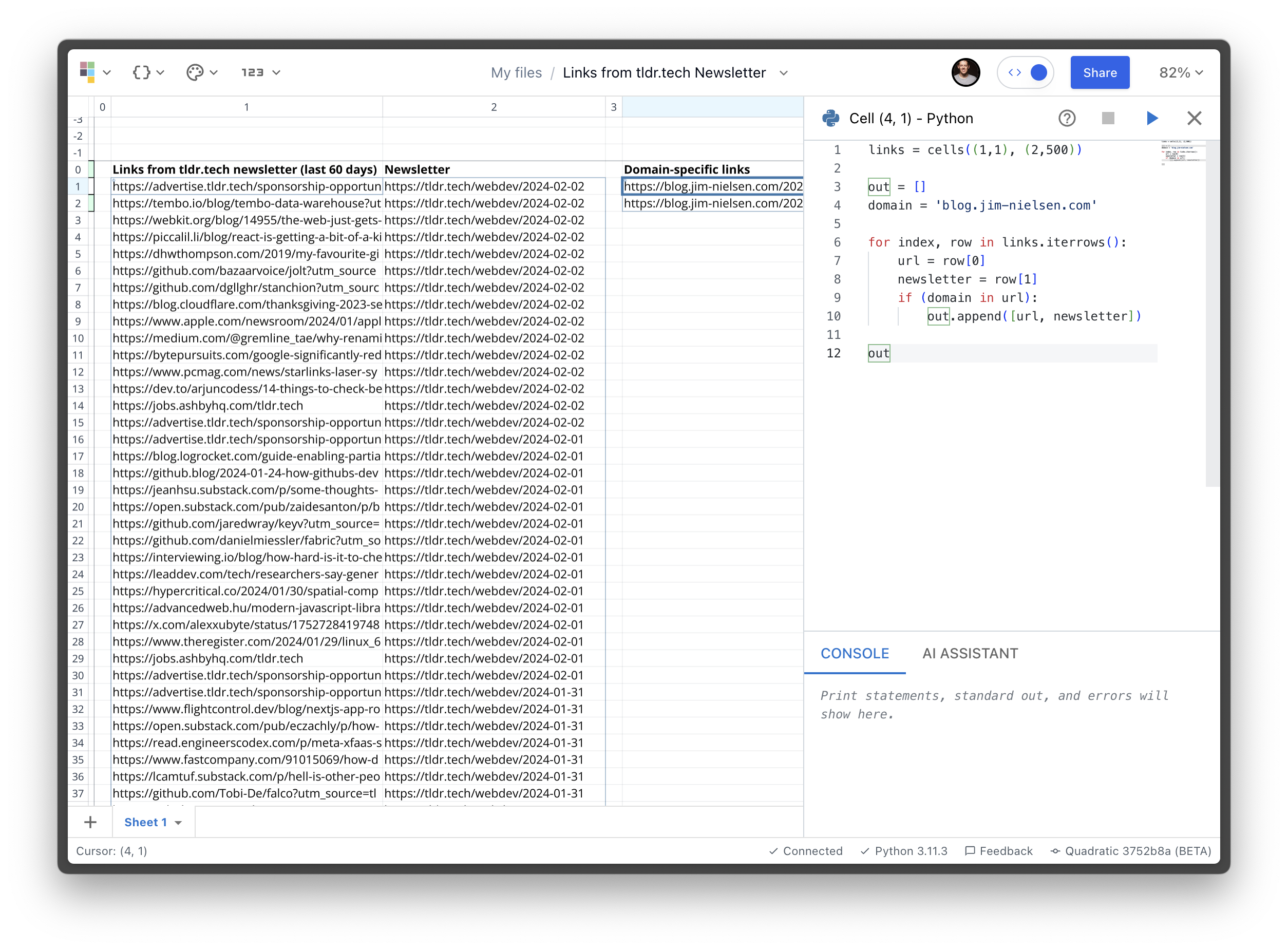
Again, annotated:
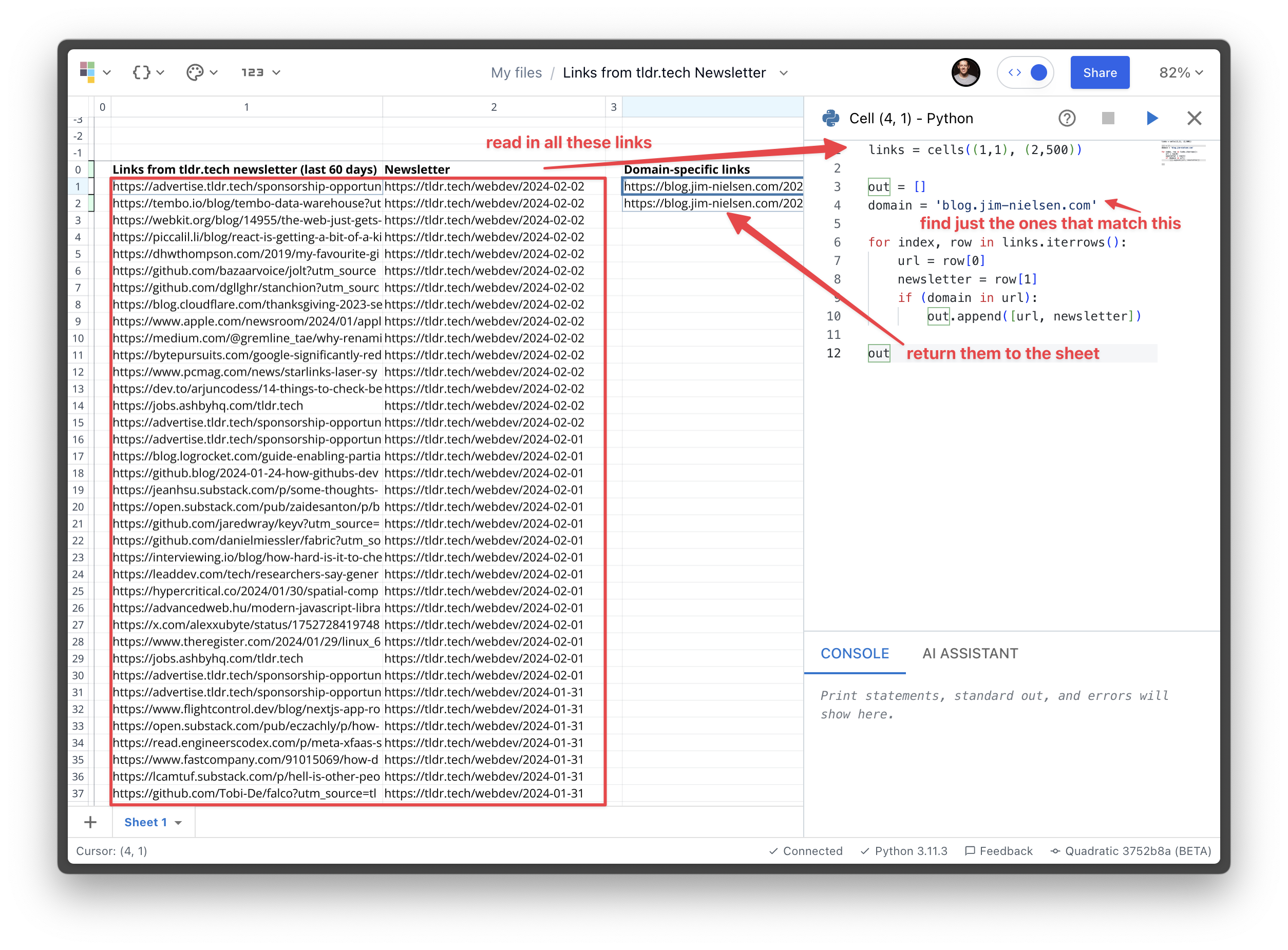
And that’s it! Pretty quickly I had found all the individual newsletters that linked to my blog. From there, it was easy to visit the link of each newsletter and find where they linked to my blog (and what they said).
And the best part was I could do all of this from my browser in a visual way. No local environment setup. No garbled strings of text in a console with me trying to parse and decipher the data. Simply fetch data, render it to a structured grid, filter/manipulate it, and find exactly what I want.
I even ended up using a couple cells as “input variables” to my script — like what domain to search for or how many days back to look — then I could change that cell and the whole script would automatically re-run. Here’s a screenshot of my final sheet:
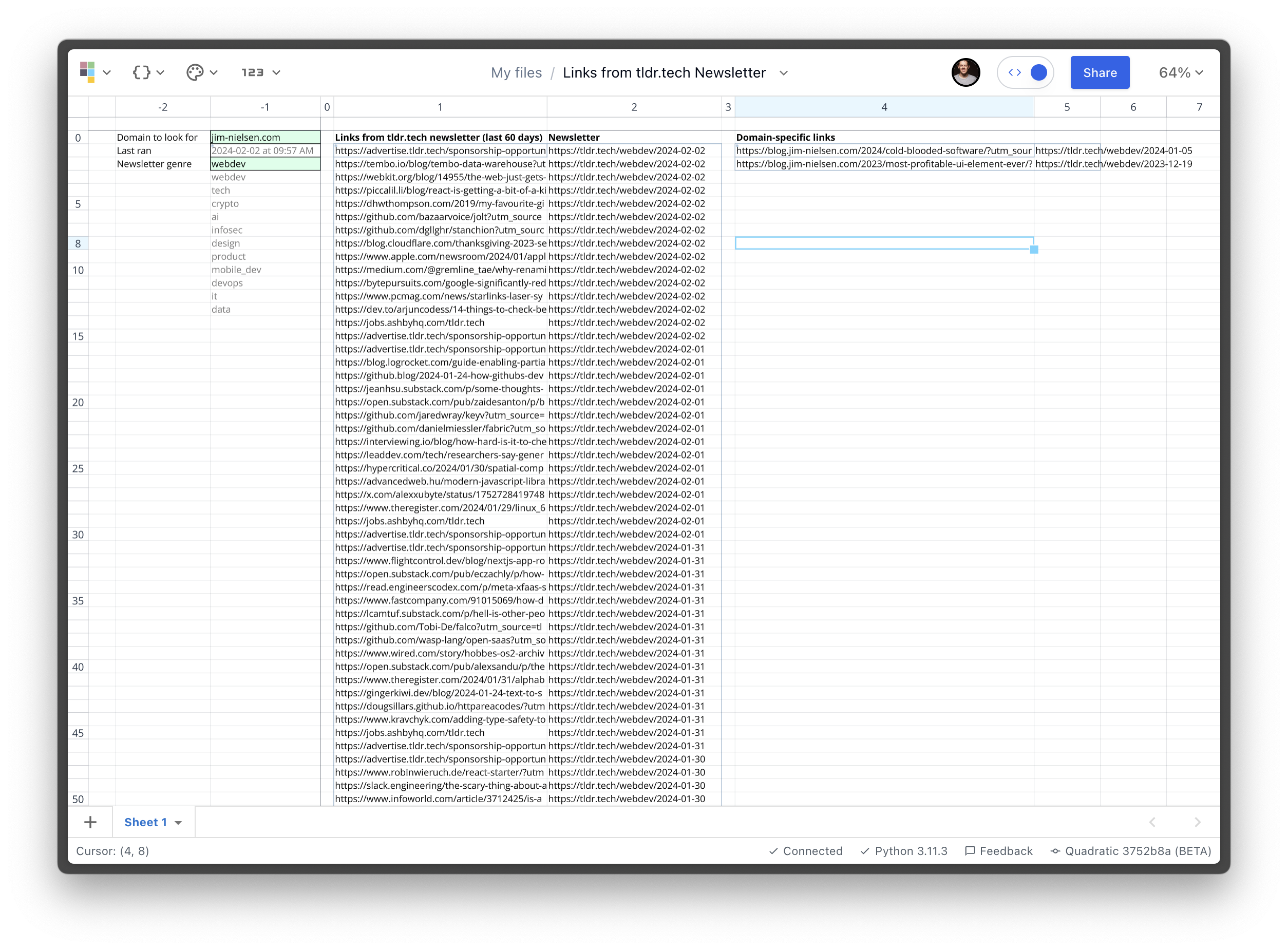
Even better than a screenshot, we recently shipped file sharing and multiplayer so you can dive right into the app and see the sheet for yourself (no need for an account):
My link parsing spreadsheet in Quadratic →
That said, you gotta have an account to clone the sheet and play with it yourself (sorry I didn’t set it to publicly editable because I don’t want my sheet messed up — not that you would dear reader, but you know, the internet).
I’ve built a fair number of little discovery tools like this in Quadratic over the last few months. I hope to share more soon.