I’ve been reading High Performance Browser Networking. In it, the author Ilya Grigorik talks about how “slow start” was built into the protocol to keep the network and its clients from overwhelming themselves. While a genius solution, it puts small short bursts — like general HTTP requests — at a disadvantage performance-wise. That’s why connection re-use is so vital to good performance. Here’s the excerpt from congestion avoidance:
TCP is specifically designed to use packet loss as a feedback mechanism to help regulate its performance. In other words, it is not a question of if, but rather of when the packet loss will occur. Slow-start initializes the connection with a conservative window and, for every roundtrip, doubles the amount of data in flight until it exceeds the receiver’s flow-control window, a system-configured congestion threshold (ssthresh) window, or until a packet is lost, at which point the congestion avoidance algorithm takes over.
I won’t pretend to fully understand that paragraph, or TCP, or “slow start”, but I understand enough to find that it interesting.
In fact, it makes me appreciate the beautiful design of TCP — which stands in contrast to so many other pieces of brittle technology — due to its resilient, even antifragile, nature. What’s antifragile? Here’s Nassim Taleb in his book on the subject:
there is no word for the exact opposite of fragile. Let us call it antifragile. Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better.
An antifragile system doesn’t just stand up against stressors, it is strengthened by them — like the body’s immune system — whereas a fragile system is “weakened, even killed, when deprived of stressors”.
This is what I find so intriguing about the nature of TCP: it performs best when it fails to do the very thing it was designed to do — deliver packets. Back to Ilya:
In fact, packet loss is necessary to get the best performance from TCP! A dropped packet acts as a feedback mechanism, which allows the receiver and sender to adjust their sending rates to avoid overwhelming the network, and to minimize latency
Failure is built into the system. Failure is reparative. Like an immune system that needs challenges to thrive.
TCP is what the other layers of the web sit on top of. Its nature of resiliency, even antifragility, can seep into the other layers which sit on top of it — if we allow it.
Further, some applications can tolerate packet loss without adverse effects: audio, video, and game state updates are common examples of application data that do not require either reliable or in-order delivery — incidentally, this is also why WebRTC uses UDP as its base transport.
If a packet is lost, then the audio codec can simply insert a minor break in the audio and continue processing the incoming packets.
When built in layers on top of TCP, URLs, and HTML[1], websites can withstand their equivalent of packet loss — the loss of CSS or JavaScript — and still function.[2] [Image borrowed from Jeremy Keith’s “Layers of the Web”.]
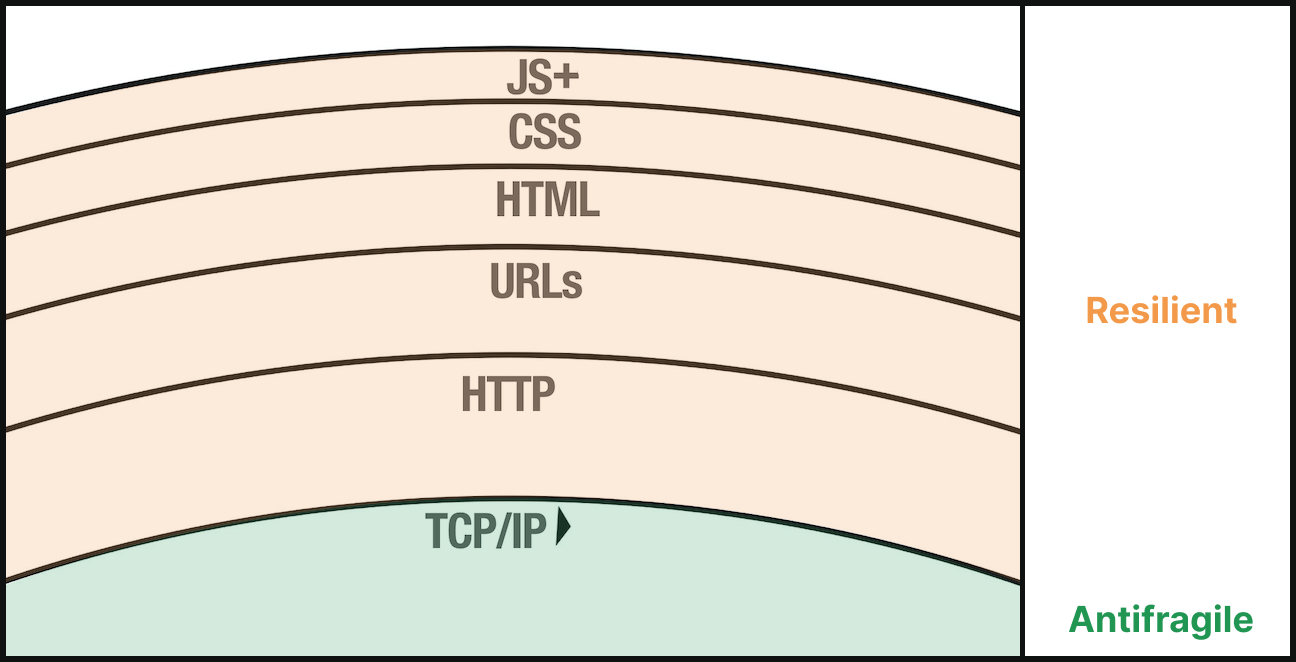
However, when you smash multiple layers into a single, interdependent layer you lose the resiliency naturally afforded by layering. One point of failure in a multi-stack layer can bring down the whole layer.
For example, when a website is architected and delivered as a giant bundle of JavaScript that contains all the logic for routing (URLs), markup generation (HTML), styling rules (CSS), and interactivity (JS), it’s easily prone to failure at the first sign of a “packet loss” or failure.
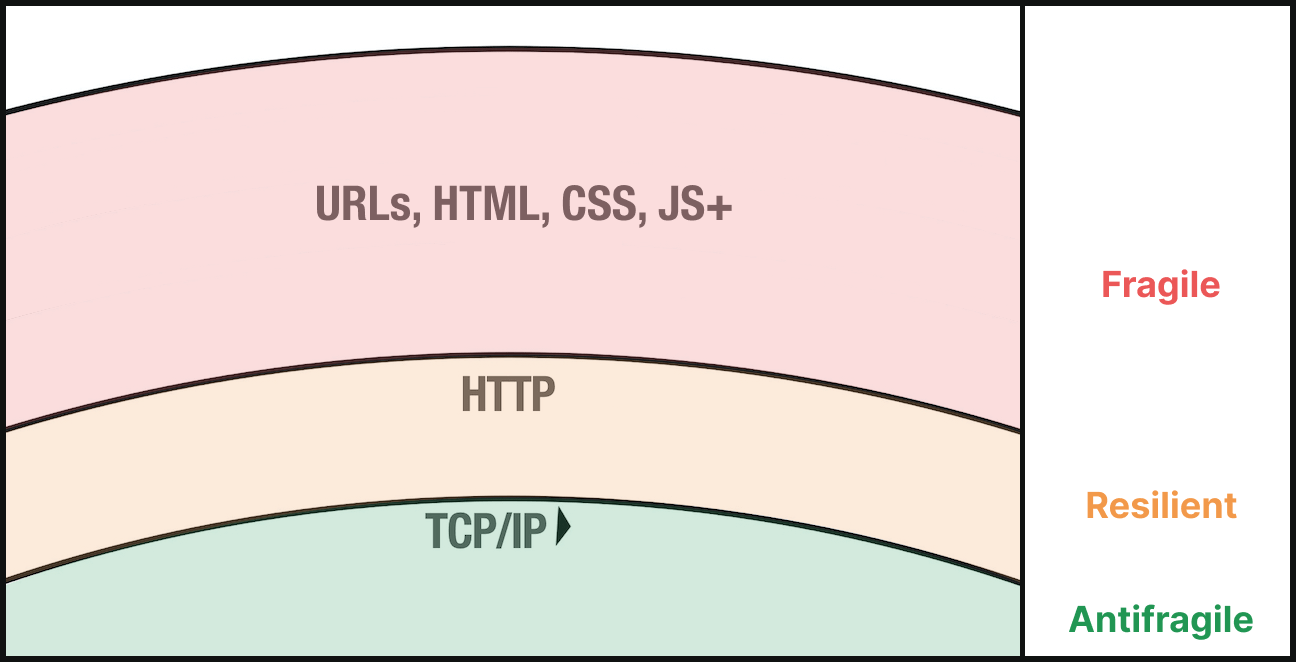
This is all to say: the web can be built in layers, with each layer’s characteristic strengths being able to seep into the ones above it — if we let them.