(Re)Introducing Readlists
I really miss @Readlists. — Me
There have been a number of “read it later” services throughout the history of the web: Instapaper, Pocket, and Readability to name a few. These functioned as services that would take the content of a web page, strip out all the cruft (ads, navigation, comments, etc.), and save the primary content into a personalized queue for later (offline) access.
Readability was my favorite “read it later” service until it was eventually shut down (I’ve paid for Instapaper ever since). During their heyday, the folks at Readability created a complementary service called Readlists that allowed you to take a collection of individual articles from anywhere on the web and package them up into an ebook (an .epub file, .mobi file, etc.). Readlists were like mixtapes but for online content.
I loved Readlists. I used it all the time to take collections of articles online and turn them into ebooks I could read on my favorite devices (kindle, iPad, etc.). This fit perfectly my preferred workflow for learning from online writing. For example, I could put together a compendium of related blog posts, or even an online book like High Performance Browser Networking, turn that content into an ebook, and then save it to a reading app (like iBooks) that let me highlight and annotate passages of text. PDFs are problematic in this regard because each page is, essentially, an image. With an EPUB file, however, I get access to the raw words, which makes working with text much easier (like copy/paste, search, etc). It’s the web at its finest: raw content, accessible in my preferred format.
After the service was killed, I found myself every few weeks thinking, “gosh, I wish that service was still up. I really need to make a readlist out these handful of articles.” Sadly, however, I’ve been out of luck for years. I’m not the only one either. The top Google search result for “readlist” (at the time of this writing) is a reddit post titled “Is there any good alternative to readlists.com?”.
After about five years of constant inner complaining—“ugh, I wish Readlists was still around“—I finally asked myself: “well then why don’t you recreate it?” By that point, I’d had enough experience programming to be naive and dangerous. I figured it’d be a fun project because it was solely for me and not for anyone else.
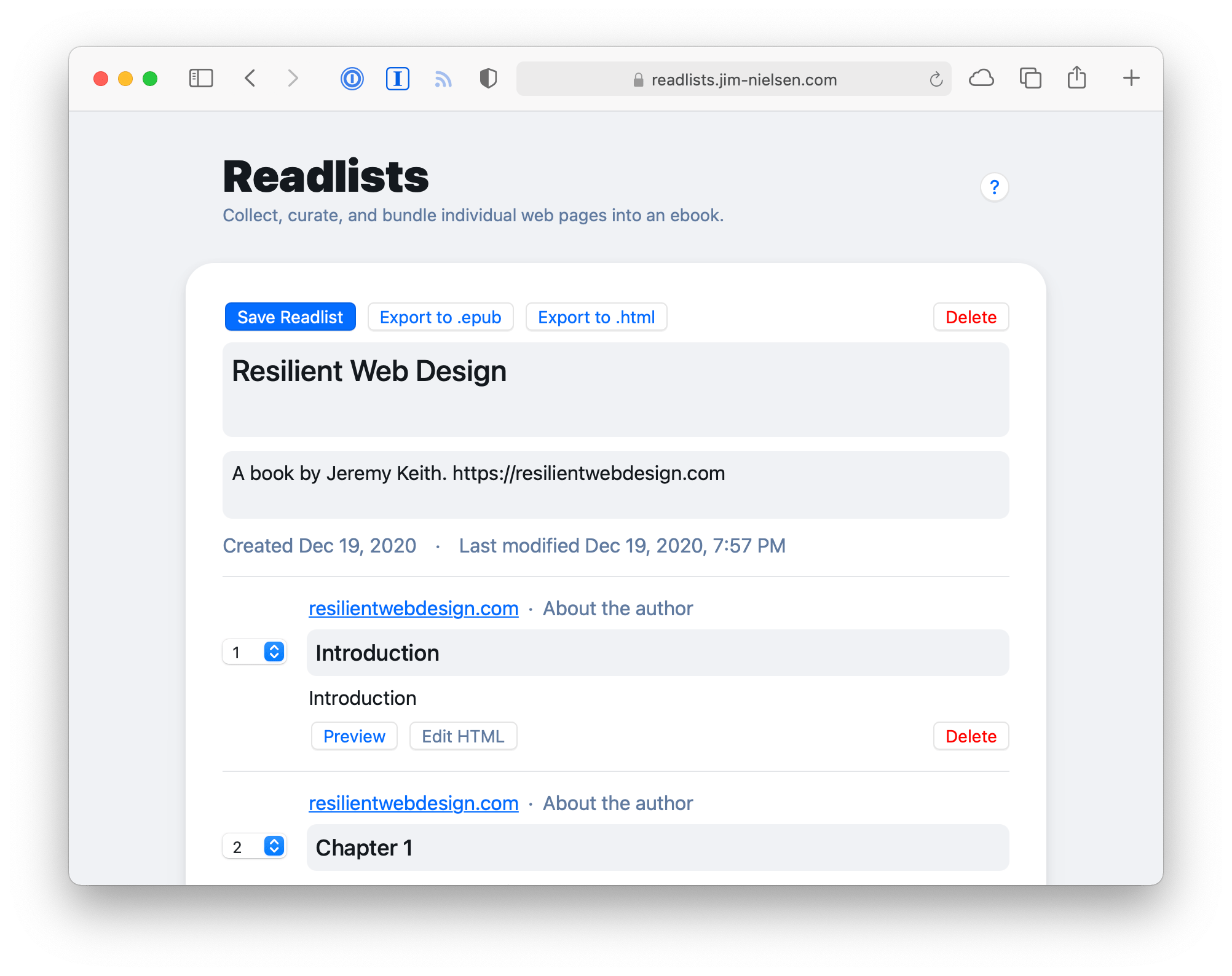
So I blatantly stole the idea and the name, then made a web UI for creating readlists. It allows me to enter a collection of URLs, tweak their titles and ordering, then turn them into one big collection of words (currently it exports to a single HTML file or EPUB 3).
How It Works
In essence, a readlist is the data provided by the mercury-parser with a few extra readlist-specific data fields. That’s it.
In that spirit, a readlist is something you can create and own forever. It’s JSON data. When you create a readlist, it is saved locally to your browser (using localStorage). Want to save it more permanently? Export the readlist to a JSON file. Want to share it with a friend? Host that JSON file somewhere and give them the public URL, which they can then import using the web GUI on readlists.jim-nielsen.com.
In short, it falls to you to save and distribute (the URLs for) your readlists. Yes, that’s more work for you, but on the flip side, the data is yours forever. Do what you want with it. readlists.jim-nielsen.com is merely a GUI for creating these JSON readlists.
A Few Example Readlists
Below are two URLs for example readlist files created by my web GUI. You can copy/paste the URLs into readlists.jim-nielsen.com and a copy of that readlist will be created in your browser. From there, you can do what you want with it.
These are example books I’ve created for myself and thus host for myself:
- “High Performance Browser Networking”
- Great book about the networks, protocols, and APIs working in the browser. It’s available for free online, but only as HTML not EPUB.
- Readlist JSON: https://cdn.jim-nielsen.com/readlists/high-performance-browser-networking.json
- “Offline” by Paul Miller
- A collection of blog posts from a writer on The Verge who took a hiatus from the internet for one year.
- Readlist JSON: https://cdn.jim-nielsen.com/readlists/paul-miller-offline.json
A Few Technical Notes
This thing is not perfect, but it (mostly) gets the job done for me. I’ve created six or seven readlists with it now, fixing bugs along the way—there are undoubtedly more. This is definitely a “use at your own risk” kind of deal.
As noted, this is a web GUI for editing the readlist JSON file. If you prefer, you can always export the raw readlist JSON data, edit it in something like VSCode, and re-import it to the web client as a readlist. That gives you ultimate control over getting an EPUB that’s juuuuuuust right for you.
I could write a whole series of blog posts on how I built this—and I just might—but for now, here’s a simple bulleted list of a few details:
- JS required. It’s a pure “client-side app”. I might changed this in the future, but this was the easiest way to prototype and get started.
- A CLI version of this would be cool! Pass in a bunch of URLs as params, a preferred format, and get back the readlist. Or, in a similar vein, an API endpoint.
- The EPUB that gets generated should be a valid EPUB3 format, but I’ve only tested this in iBooks and on the Remarkable tablet—just full disclosure.
- This is merely one front-end. If somebody else wants to build their own front-end, do it! I envision readlists as more like an open file format than a proprietary platform. Imagine all kinds of clients reading/editing/creating readlists based on a standardized format.
The site is hosted on Netlify and takes advantage of their rewrites/proxies capabilities. The source code is on Github. Feedback, comments, ideas are welcome.