CSS For URLs and HTTP Headers
A couple things have been swirling in my head:
- Chris Coyier’s post about flash of inaccurate color theme (FART) becoming an official term.
- Jason Lengstorf’s post about achieving a theme switcher without a flash of inaccurate color by using Netlify’s edge functions.
- My post about npm dependency queries and their special selector syntax, like the
:semver()pseudo class
These all got thinking…
When you’re looking at a webpage, what you have underneath is the DOM:

Whoops, wrong DOM. Here we go (image courtesy of Wikipedia).
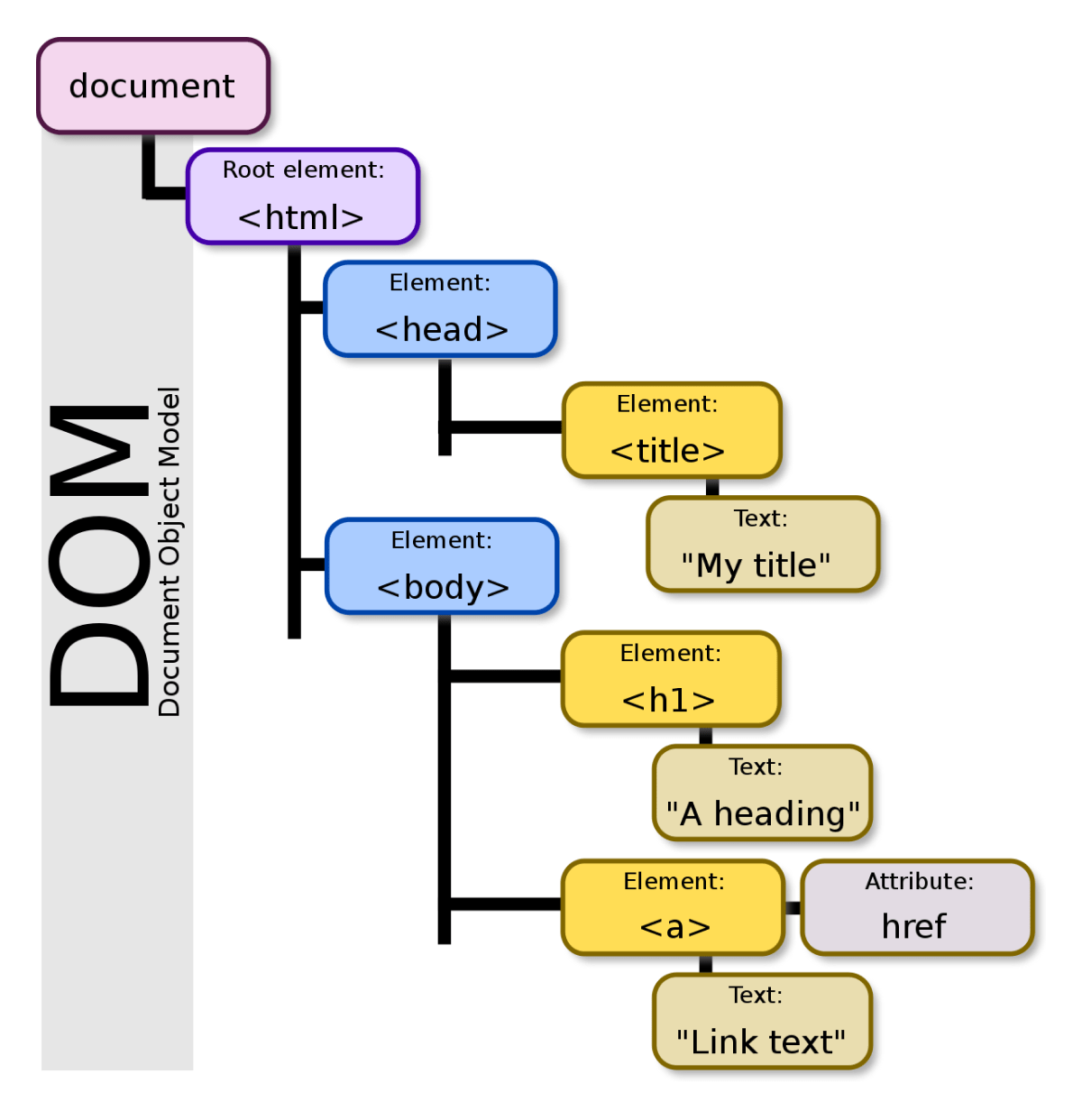
How do we get the DOM? The browser knows how to create it from an HTTP request consisting of a URL, some headers, and some HTML. For example, this is a simplified representation of (the beginnings of) the webpage for www.jim-nielsen.com.
> GET / HTTP/2
> Host: www.jim-nielsen.com
>
< HTTP/2 200
< content-type: text/html; charset=UTF-8
< date: Tue, 15 Nov 2022 19:47:19 GMT
< content-length: 475979
<
<!DOCTYPE html>
<html lang="en">
<head>…</head>
<body>…</body>
</html>
Note the different pieces of information that are entangled in that HTTP request: a URL, some headers, and some HTML. The browser knows how to take all that information and render it as a webpage.
The HTML is normally what we think of when we’re using CSS to style a webpage (e.g. “if there is an element with the class .foo make the text color: red”). However, more than just the information in the HTML can be useful when styling a webpage. The HTTP request has pertinent information, like the URL and headers, which we have no way to query and logically apply styles based upon.
I suppose you can do this today, at least in small part, with something like the :target pseudo class which allows you to target and style a specific element in the DOM based on the value of the fragment in the URL (beware: it has its quirks like history.pushState not affecting :target styles).
My point is: there can be information critical to styling a webpage that lives outside of the HTML alone. The entire HTTP response remains inaccessible to CSS. Why is that? What if you could write selectors based on any piece of information in the HTTP response?
URL Selector: The @document Rule
Turns out, there is/was a @document at-rule — proposed in CSS3, deferred to CSS4, seemingly deprecated now? — which allows you to write styles applicable to specified URL(s). This would be awesome for writing domain-specific user styles, but also (I think) for author styles.
/* Only apply these to the specified URL */
@document url("https://blog.jim-nielsen.com/about/") {
body {…}
}
The proposed syntax allows matching rules based on a URL’s value, prefix, or domain. If that’s not enough, there’s a way to match based on a regex.
/* Apply these to all URLs that start with 'https:' */
@document regexp("https:.*") {
body {…}
}
Regexes are great, but I wonder how accessible they are to a lot of folks? And while there’s a proposed @document url-prefix() it makes you wonder, “What about @document url-suffix()?” And nothing I’ve seen touches on how to style based on query params (I suppose that’s what the regex is for?).
Part of me wonders if, instead of these enumerated functions (url(), url-prefix(), domain(), regex()) could we instead leverage the existing idiom of CSS attribute selectors? I’m not sure what the syntax would look like, but imagine this as an example:
/* URL matches exactly */
@document[url="https://blog.jim-nielsen.com/about"] {…}
/* URL contains somewhere (query params FTW!) */
@document[url*="foo=bar"] {…}
/* URL starts with */
@document[url^="https:"] {…}
/* URL ends with */
@document[url$=".php"] {…}
/* Domain is */
@document[domain="jim-nielsen.com"] {…}
/* Domain is AND URL ends with */
@document[domain="jim-nielsen.com"][url$=".html"] {…}
Granted I’m spitballing here, but that’s what blog posts are for.
HTTP Selector…?
As far as I know, nobody has asked for CSS selectors that can query HTTP headers. There’s probably reasons for that, but again I’m imagining.
Setting aside the open-ended possibilities people might dream up with non-standard X- headers, imagine being able declare some styles based on the presence of a cookie. Cookies are interesting because they are a piece of state set by the server and sent by the client on every subsequent request — no JavaScript needed!
This could be incredibly useful for supporting a use case like user-configureable dark mode without FART on a static file host. You send a user to the appropriate URL, the server sets a cookie, and now you have a piece of state the CSS can query. No edge function HTML rewrite necessary, no flash of inaccurate color theme spotted, and no client JavaScript needed! Example CSS:
/*
Imagine some HTTP response headers like this:
< HTTP/2 200
< set-cookie: THEME=dark; path=/; domain=…
And you style based on that!
*/
/* Light mode */
:root { background: #fff }
/* Dark mode via system preference */
@media (prefers-color-scheme:dark) {
:root { background: #000 }
}
/* Or dark mode via user preference */
:http([set-cookie*="THEME=dark"]) {
:root { background: #000 }
}
There are probably lots of reasons we can’t do something like this — but this is my blog and it’s where I dream!