A Collection of Reading Notes
I was listening to Dave and Chris on the Shop Talk Show #445 talking about content strategy on their sites.
Around 32:00 Dave was talking about how he started doing “Week Notes” on his blog: he’d read something then link to it and quote whatever stood out to him.
However, he’d come to regret his “Week Notes” because he could never go back and find specific links since all the posts were named the same. He could remember linking to something but didn’t know where that something might be.
I had a similar problem. I create a monthly post called “Reading Notes” which are a collection of links and and excerpts from my online readings.
Like Dave, I was always looking for something I’d linked to based off a vague memory of a keyword, but never knowing where to find it.
My solution used to be either 1) do a Google site search of my blog, or 2) open my blog’s codebase in VSCode and do a keyword search across all *.md files.
In trying to solve this dilemma, I faced a lot of existential questions about my blog (Why do I even write reading notes as blog posts? Shouldn’t they be their own post type like links on adactio.com? Should I start a different site? Who I am? etc.). Fortunately, I was able to stop myself short of doing something drastic and instead start small.
On my blog today, I have a /tags page that serves as an index of every tag on my site and its associated posts.
Lucky for me, I’ve been tagging my monthly “Reading Notes” posts for years, so if I go to /tags#readingNotes I can see a list of every “Reading Notes” post I’ve ever done.
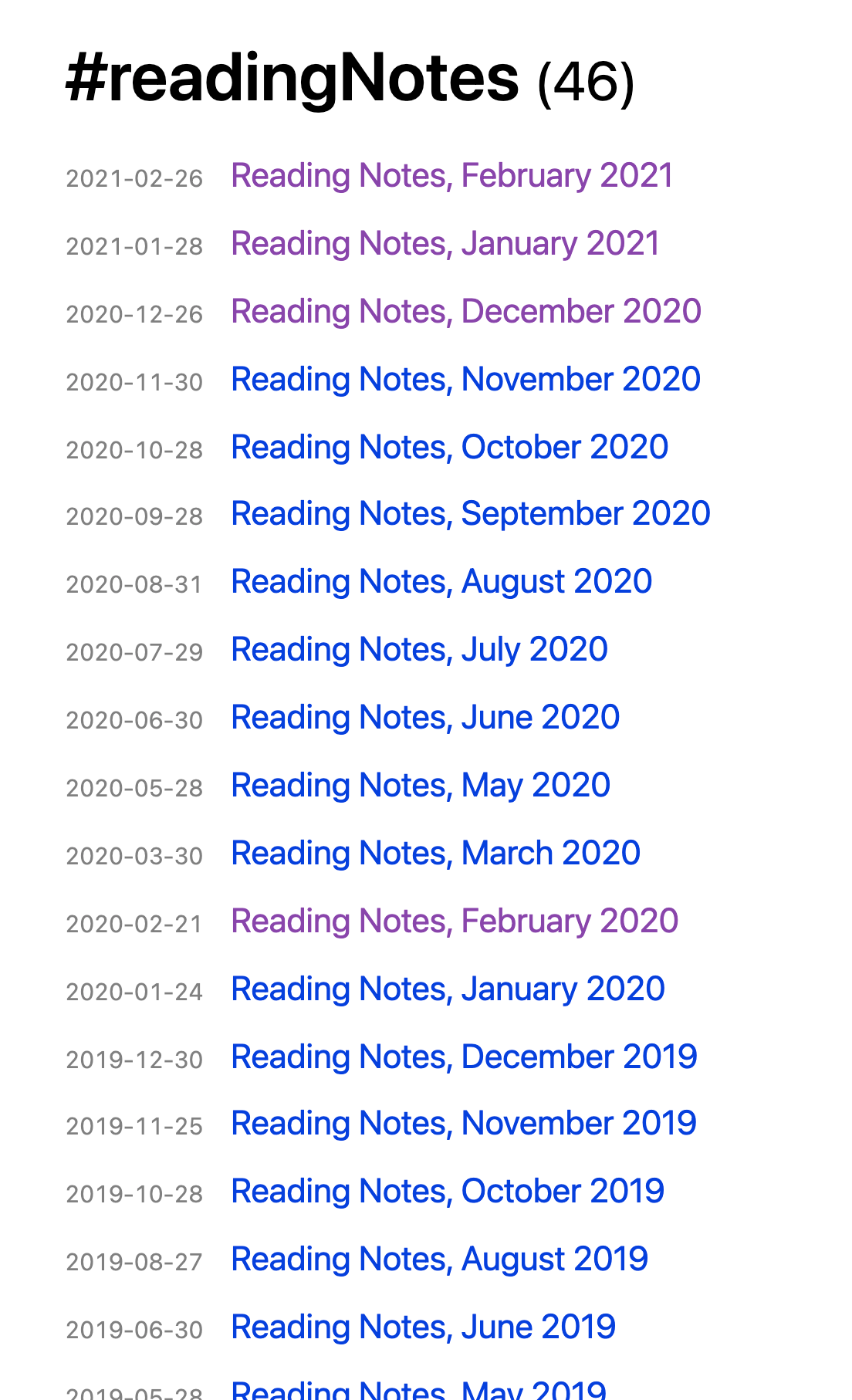
The problem here is the same one that Dave described: these are just chronologically-named posts that don’t give me any clue into their contents.
“What would be great” I thought, “is if I could just see the contents of all these posts right here inline.”
How convenient for me that I control my own blog. And how convenient for me that my current URL scheme had a logical place for something like this to live:
/tagsis a page that lists all tags and their associated post titles with links/tags#:idanchors me to a particular tag and its posts
/tags/:idcould be a page with all posts under that tag and their post content
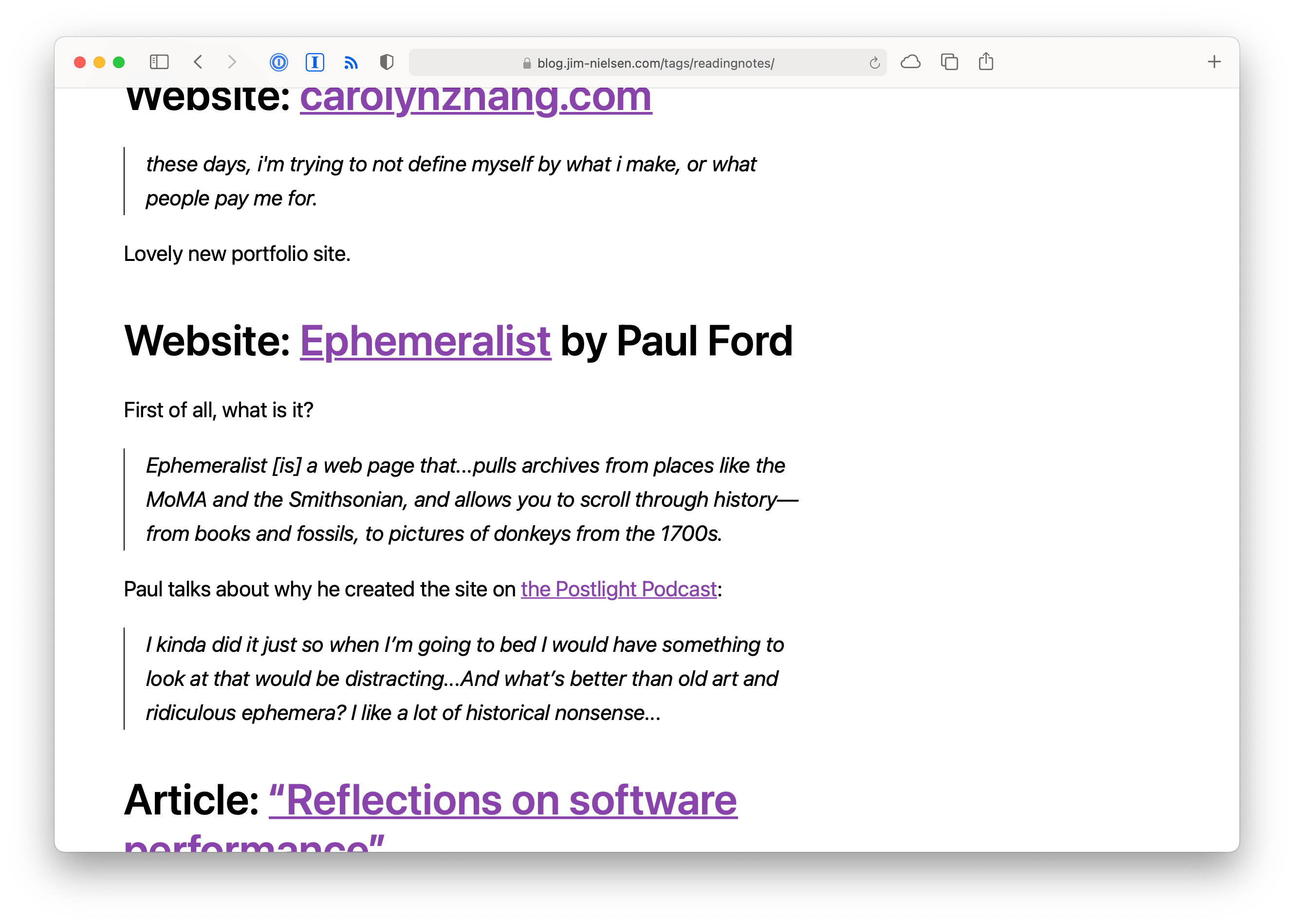
I went ahead and made that: /tags/readingNotes. I didn’t do it for every tag, only #readingNotes because that’s what was useful to me (plus this page is essentially pure text—just a whole bunch of HTML representing the content of every “Reading Notes” post I’ve ever done).
The effort to make this happen on my blog was incredibly small. You can see the commit on Github: a new file that takes my site’s data—already being used elsewhere in my static site generator—and runs it through a template for this specific page.
I don’t link to this page in my site’s navigation because it’s intended as a tool for me. But if you follow my blog, you now know about it (exclusive insider content).
I wasn’t planning on doing a writeup about this change. However, after listening to Dave and Chris talk about a similar problem on their podcast I thought, “hey I’m not the only one.”
Now when I need to find something that I know I linked to once in my “Reading Notes” posts, I go to /tags/readingNotes, hit CMD+F in my browser, and start doing a keyword search. Boom! Search for free.
I love browsers. The right combination of HTML and URLs is amazing.