The Web as an Information System
I was recently watching a talk from Rich Hickey on YouTube titled “The Database as a Value”. There are some great insights in that talk, even though many of them are a bit over my head as a mere “web designer”.
But I want to focus on a particular part of Rich’s talk, which starts here and goes for about a minute. My transcript:
Databases change...the question is: do they change change in place? Or do they change by growing? Most traditional databases change in place...They forget everything they ever knew every time you tell them something new...How many of you keep your source code in a directory and every time you change a file you just overwrite the directory? [No!] We're programmers and we know what we need: we need every version we’ve ever made. And what’s on every version? “When”! It grows.
He continues:
A database that updates in place is not an information system. A real information system should accrete facts. It should accumulate—because that’s what happens in the world...[an information system needs to gather the stuff that happens in the world, not pretend to be the world]. It’s supposed to record information about what happened in the world. The past does not change. If you’re an information system, you have to record what happened in the past, you don’t go back and fix it.
I find this notion of an “information system”—an entity that accretes over time instead of overwriting in place—relevant to what the web is and what it could be.
When we said “Obama is now the President of the United States”, that was a fact that accreted into the information system that is history. We didn’t “overwrite” Bush and he got completely forgotten and erased from memory. When a person asks, “who is the President of the United States?” that question has a kind of implicit notion of time baked into it with the use of the word “is”: “who is the President of the United States?" is different than “who was the President of the United States?”. And the “was” question could only ever be answered by specifying a when (“who was the President of the United States in 1912?”). And just to show how murky language can be, the notion of time in the first question could also be modified by specifying a when (“who is the President of the United States in 1912?”)
What am I getting at with all of this?
It feels like a shame that the colloquial practices of building for the web never fully amounted to building with this kind of “information system” in mind, i.e. an immutable system that accretes over time, never going back and fixing things in place. Just imagine if the architecture of the web allowed such that you could “add a second parameter” of time to the URL bar in a browser. Sure, the default would be what it is today: you type in a URL and it implicitly means “take me jim-nielsen.com _as it is today_”. But the web was an information system would support typing in a URL and a time parameter, allowing you to state “take me to jim-nielsen.com on June 20, 2012.” That would be incredible! Every version of your site, your site’s content, your styles, your interactions, all of it preserved. It’d be a geological record of any given domain through time! Instead, we’ve had to rely on things like the Wayback Machine for this kind of functionality.
In contrast to the above approach, today’s web is (culturally and technologically) built around the idea of a URL being mutable. jim-nielsen.com today might not be the same as jim-nielsen.com tomorrow. And while some (mostly tech-savvy folks) try to live by the idea that “Cool URIs don’t change”, I think the reality is (at least in terms of public expectation and perception) that URIs do change. They rot. If you picked up a printed book from 2001 that had a URL in it, I think most people wouldn’t expect that URL to work. And even if it did, even if the content at that URL was the same, it might not be the same style and appearance that it was when that URL was printed.
I’ve seen some novel attempts at this kind of preservation. Tyler Gaw has something like this on his website, where he displays and links to iterations of his site over the years.
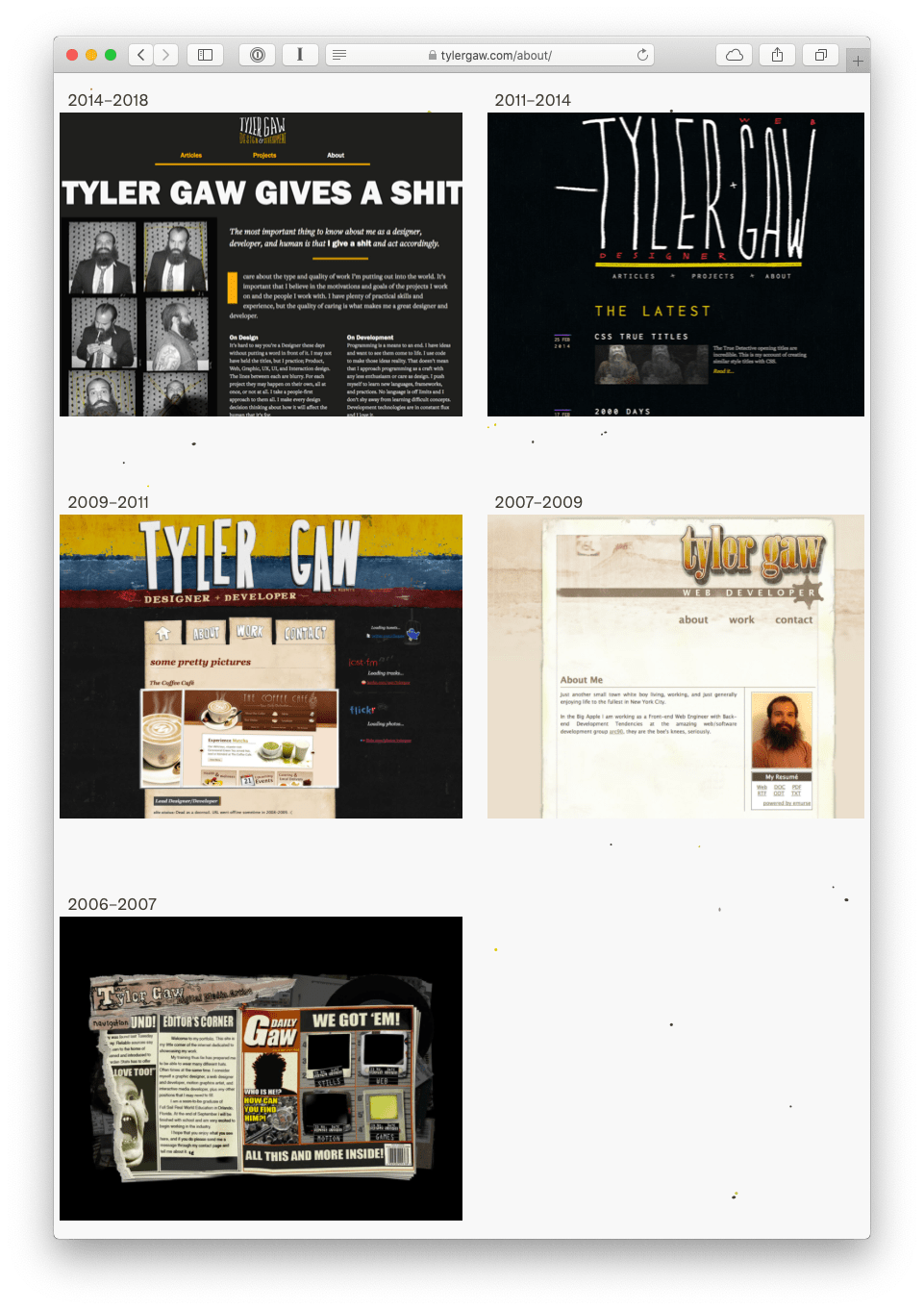
I’ve been wanting to do something like that. But it’s hard. I don’t have all the code, assets, etc., laying around from previous versions of things I did. It really feels like this kind of approach to building things is a mindset. And I’d like to start changing my mindset. If this conceptual notion of time was part of the fabric of how we built for the web, perhaps we really could arrive at a true “information system” of the kind Hickey described in his talk. Einstein merged space and time into spacetime. Imagine if we could change the architecture of the web such that we didn’t just have URLs, we had URLtime?
You might say, “but sites like blogs already do this: they bake time into the URL, i.e. /posts/2020/name-of-post.html” But even that approach isn’t a guarantee that that URL as viewed today will be identical to how it’s viewed 5 years from now. As Paul Robinson says in his post, “Immutable URLs”
think for a moment about your first ever blog post. Sure would be interesting to go read that today exactly as it was then.
That kind of information system would be a world treasure.