The Nuance of “Domain”
I love visualizations like this:
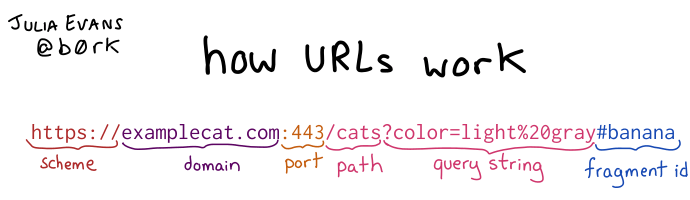
That was my mental model of URLs until I indexed my blog’s links and realized there’s more to “domain” than initially meets the eye.
What is a “Domain”?
Let’s say you have a URL like this:
https://example.com
Put it in the URL constructor and you’ll get its component pieces:
{
"origin": "https://example.com"
"protocol": "https:"
"hostname": "example.com"
// more...
}
Where’s “domain”? It’s not in there anywhere…
But wait, hostname is probably what we’re thinking of, right? example.com
But if your URL is:
https://www.example.com
The hostname will be:
www.example.com
Similarly, if your URL is:
https://subdomain.example.com
Your hostname will be:
subdomain.example.com
So the question is: if you have a ton of links and you want to group them by “domain” — like I did — how do you pull the “domain” out of each URL?
For example, for an unknown set of links like this:
https://gist.github.com/user/123abc456defhttps://www.github.com/path/to/thinghttps://github.com/jimniels/bloghttps://google.com/q=foohttps://www.google.com/q=bar
You would want to count them by “domain” and get a result like this:
{
"github.com": 3,
"google.com": 2
}
Get the Domain Programatically
You might think, “get the hostname from the URL, split the string by periods (.), and join the last two items in the array”.
new URL("https://www.example.com")
.hostname // "www.example.com"
.split(".") // ["www", "example", "com"]
.slice(-2) // ["example", "com"]
.join(".") // "example.com"
That seems sensical, right?
The problem is, the word “domain” starts to get fuzzy and its anatomy has no universal rule for consistent parsing (such as “everything after the last period is the top-level domain”).
For example, here’s a valid domain that breaks our logic:
https://example.co.uk
In that case, we don’t want co.uk as the “domain”. We want example.co.uk.
Turns out, “domain” is a loaded term so let’s talk about words.
Top-level Domains, Domain Names, Subdomains, Root Domains, Domains, Domains, Domains!
Given a traditional URL like this:
https://www.example.com
It’s easy to think this dissects to:
.comis the top-level domainexampleis the domain namewwwis the subdomain
But giving these things names based on position gets confusing because it’s never 100% uniform.
Again, this URL breaks expectations of naming based on positioning:
https://www.example.co.uk
This is (I believe) why you’ll sometimes see the parts of the domain referenced simply with numbers, e.g. top-level, second-level, third-level, fourth-level, and so on. (Image courtesy of webmasters.stackexchange.com.)

So, as I’ve discovered, if you want to grab the “domain” (as I’ve colloquially thought of it) across a set of links, what you probably want is the “effective top-level domain” or “public suffix” which is available at publicsuffix.org.
Since there is no algorithmic method of finding the highest level at which a domain may be registered for a particular top-level domain (the policies differ with each registry), the only method is to create a list of all top-level domains and the level at which domains can be registered. This is the aim of the effective TLD list.
Need access the list programmatically from JavaScript? There’s an NPM Package For That™️: psl.
import psl from 'psl';
const parsed = psl.parse('a.b.c.d.foo.com');
console.log(parsed.domain); // 'foo.com'
Per our example from earlier, now we can properly extract the “domain” from a URL:
import psl from 'psl';
const { hostname } = new URL("https://www.example.co.uk")
const parsed = psl.parse(hostname);
console.log(parsed.domain); // 'example.co.uk'
Conclusion
Back to that graphic I started this post with:
This graphic could lead you to believe the “domain” is a simple, straightforward part of the URL. But, as with many things in computers, the term is used loosely and its definition comes under scrutiny when dealing with the nitty gritty details of parsing URLs.
This is the nuance of the word “domain”.